
Anfang
Im letzten Kapitel haben wir von Verfahren gehört, mit denen eine datenbasierte KI entwickelt werden kann: Das maschinelle Lernen (englisch “machine learning”).
Maschinelles Lernen sind Verfahren, mit denen man Muster in Daten finden kann und aus diesen etwas lernen kann. Das Gelernte wird dann von einer datenbasierten KI genutzt, um eine bestimmte Aufgabe zu erfüllen. Den Vorgang des Lernens nennt man Training. Oder anders gesagt: Die KI wird mit Daten trainiert.
Maschinelles Lernen kann in drei Teilbereiche unterteilt werden:
- Unüberwachtes Lernen (englisch “unsupervised learning”)
- Überwachtes Lernen (englisch “supervised learning”)
- Verstärkendes Lernen (englisch “reinforcement learning”)
Wir werden uns in diesem Kapitel die Methode überwachtes Lernen genauer anschauen am Beispiel einer konkreten Anwendungsmöglichkeit von KI. Nach einer kurzen Einführung des Ablaufs folgt ein praktischer Teil, bei dem wir eine eigene KI trainieren werden. Dabei lernen wir nicht nur, wie maschinelles Lernen in der Umsetzung ablaufen kann, sondern werden auch Erkenntnisse gewinnen über die Möglichkeiten und Grenzen von KI.
Die zwei anderen Formen von maschinellem Lernen (unüberwachtes Lernen & verstärkendes Lernen) und andere Anwendungsbereiche von KI im Bildungsbereich werden wir im nächsten Kapitel kennenlernen.
Wie funktioniert überwachtes maschinelles Lernen?
Im ersten Kapitel haben wir bereits eine KI kennengelernt, die mithilfe von überwachtem maschinellem Lernen trainiert wurde, um ihre Aufgabe bewältigen zu können. Zur Erinnerung:
Erkennen von spitzen und stumpfen Winkeln
Der KI wird ein Foto von einem gezeichneten Winkel gezeigt und diese sagt uns, ob sie einen spitzen oder stumpfen Winkel erkennt.

Diese KI hat aus einem großen Datensatz gelernt, wie man spitze und stumpfe Winkel voneinander unterscheiden kann. Dafür hat man ihr ganz viele Beispiele von spitzen und stumpfen Winkeln gezeigt und während dem Training wurde gelernt, wie man diese voneinander unterscheiden kann. Sie zählt also zu den datenbasierten KIs.
Anhand von diesem Beispiel wollen wir uns jetzt genauer anschauen, wie überwachtes maschinelles Lernen abläuft.
Wo ist das Wissen der KI? Wie wird es genutzt?
Während dem Training lernt die KI, wie sie spitze und stumpfe Winkel richtig unterscheiden kann. Dafür muss sie in irgendeiner Form Wissen abspeichern, auf deren Grundlage dann später entschieden wird, welche Einordnung zurückgegeben wird.
" In welcher Form ist das Wissen innerhalb der KI repräsentiert? Wie wird dieses Wissen genutzt, um eine Bewertung abzugeben? "
In diesem Abschnitt gehen wir auf eine häufige Form der Wissensrepräsentation ein namens künstliche neuronale Netzwerke. Es gibt allerdings auch noch andere Formen.
Zunächst einmal führen wir einen neuen Begriff ein: Das Modell ist das Ergebnis, welches wir nach dem Training bekommen. Es modelliert ein bestimmtes Verhalten. In unserem Beispiel: Das Einordnen von Winkeln.
Das Modell besitzt Eingaben (oben) und Ausgaben (unten). Welche und wie viele ist abhängig davon, was das Modell tut. In unserem Beispiel würde das Modell als Eingabe ein Bild von einem gezeichneten Winkel bekommen und uns als Ausgabe eine Bewertung in spitz oder stumpf zurückgeben.
Unter dem Modell beim maschinellen Lernen versteht man nur den Teil eines Systems, der aus Daten gelernt hat. Ein Modell ist oft ein Teil von einem KI-System, welches noch viele andere Bestandteile hat. Zum Beispiel kann die Ausgabe des Modells genutzt werden, um etwas zu steuern. Das wäre dann nicht mehr Teil des Modells, aber immer noch Teil des KI-Systems.

Ein Bild liegt im Computer als zweidimensionales Raster an Farbwerten vor. Das bedeutet, das Modell bekommt genauer betrachtet jeden einzelnen Bildpunkt (auch Pixel genannt) im Bild als eigene Eingabe. Für ein Bild mit einer Auflösung von 256x256 wären das also 65536 Eingaben.
Die Ausgabe dagegen kann durch einen einzelnen Wert zwischen 0% und 100% realisiert werden, wobei ein Wert näher an 0% eher stumpf bedeutet und ein Wert näher an 100% eher spitz bedeutet. Dadurch kann das Modell auch Unsicherheit ausdrücken, indem es einen Wert näher an 50% zurückgibt.
Innerhalb des Modells werden alle Eingabewerte (also alle Farbwerte der Pixel) in einer großen Berechnung miteinander verrechnet. Das Ergebnis der Berechnung liefert den Ausgabewert, welcher in diesem Fall ein Wert zwischen 0% und 100% ist. Je näher die Ausgabe an 0% ist, desto mehr schätzt das Modell den Winkel als stumpf ein. Umgekehrt stehen Werte näher an 100% für einen spitzen Winkel.
Diese Berechnungsformeln sind in der Regel sehr lang und der in der Grafik gezeigte Ausschnitt ist nur ein verschwindend kleiner Bruchteil. Neben Addition und Multiplikation kommen auch noch andere Rechenoperationen vor, die hier nicht gezeigt sind.

Schaut man sich die Berechnung im Modell genauer an, findet man neben den Eingabewerten auch eine große Anzahl an Parametern. Parameter sind Werte in der Berechnungsformel, die man anpassen kann. Indem man diese Parameter verändert, ändert sich auch die Berechnung und damit das Ergebnis der Berechnung für ein bestimmtes Bild.

Das bedeutet:
Das Verhalten des Modells kann über die Parameter angepasst werden.
Ob unser Modell nun einen Winkel als spitz oder stumpf bewertet, hängt von den Werten dieser Parameter ab. Also kann man sagen:
Beim maschinellen Lernen steckt das Wissen in den Werten der Parameter des Modells.
Über die Parameter kann auf vielfältige Art und Weise gesteuert werden, worauf das Modell achtet. Würde man zum Beispiel die Parameter so wählen, dass Farbwerte an den Rändern des Bildes mit null multipliziert werden, dann hätten die Farbwerte an den Rändern keinen Einfluss auf das letztendliche Ergebnis. Also das Modell würde demnach nicht darauf achten, was im Randbereich der Bilder zu sehen ist.
Über die Parameter können allerdings auch komplexere Merkmale erkannt werden, wie zum Beispiel eine Linie. Wechseln die Farbwerte schlagartig, wenn man zum Beispiel erst einen hohen Wert (helle Hintergrundfarbe) und ein paar Pixel weiter einen niedrigen Wert (dunkle Farbe der Linie) hat, kann ein großer Parameterwert an der richtigen Stelle in der Berechnung dafür sorgen, dass das Ergebnis von dem Vorhandensein einer solchen Linie anhängt.
Es mag vielleicht schwer vorstellbar sein, dass es möglich ist, durch solch eine Formel ein Verhalten wie das Klassifizieren von Winkeln oder noch komplexeren Aufgaben umzusetzen. Allerdings ist diese Formel, wenn man sie aufschreiben würde, sehr lang und in ihrer Länge und über eine große Anzahl an Parametern lassen sich auch komplexere Aufgaben wie diese durch eine Berechnung lösen.
Das Ziel beim überwachten maschinellem Lernen ist es, geeignete Werte für die Modell-Parameter zu finden und damit ein gewünschtes Verhalten zu erreichen.
Bei der Entwicklung mit maschinellem Lernen wird nicht für jede KI-Anwendung eine komplett eigene Berechnungsformel von Grund auf neu erstellt. Stattdessen gibt es Vorlagen für diese internen Berechnungsstrukturen, die dann über die Parameter so angepasst werden, dass sie eine gewünschte Aufgabe erfüllen. Eine wichtige Aufgabe für die EntwicklerInnen beim maschinellen Lernen ist es, eine geeignete Vorlage auszuwählen.
Die Struktur der Berechnungsformel ist unter anderem bestimmt durch eine vernetzte Struktur, die man künstliche neuronale Netzwerke nennt. Dieser Begriff könnte dir eventuell bereits vertraut sein. In diesen Lernmaterialien gehen wir nicht weiter darauf ein, wie künstliche neuronale Netzwerke aufgebaut sind, denn für uns reicht es aus zu verstehen, dass diese nur die Struktur für die interne Berechnungsformel vorgeben.
Wie funktioniert das Training des Modells?
Wir wissen jetzt, dass wir die Parameterwerte richtig setzen müssen, damit das Modell in der Lage ist Winkel zu klassifizieren. Aber:
" Wie findet man die richtigen Parameterwerte? "
Beim maschinellen Lernen nutzen wir Daten, um das Modell zu trainieren. Während dem Training werden die Parameterwerte innerhalb des Modells angepasst, auf Grundlage dieser Daten.
Die Daten, mit denen das Modell trainiert wird, nennt man Trainingsdaten. Diese zeigen dem Modell, was es lernen soll.
In unserem Beispiel bestehen die Trainingsdaten aus Bildern von gezeichneten Winkeln und der dazugehörigen Klasse. Das heißt, zu jedem Bild liefern wir auch die Information, ob es sich um einen stumpfen oder spitzen Winkel handelt.
Schauen wir uns jetzt Folgendes an:
" Wie ermittelt man aus den Trainingsdaten die Parameterwerte? "
Zunächst werden die Parameter des Modells auf einen Startwert gesetzt, oft sind das zufällige Werte. Gibt man dem Modell jetzt ein Bild als Eingabe bekommt man, was zu erwarten war, eine komplett willkürliche Ausgabe. In diesem Beispiel haben wir ein Bild von einem stumpfen Winkel und das Modell gibt den Wert 65% (also eine leichte Tendenz zu “spitzer Winkel”) zurück. Allerdings wissen wir für dieses Bild, dass die Ausgabe 0% (also eindeutig “stumpfer Winkel”) sein sollte. Man könnte jetzt versuchen, die Werte der Parameter zu verändern, um das Ergebnis zu verbessern.

Um herauszufinden, wie die Parameter verändert werden müssen, nutzt man eine mathematische Methode, die sich Gradientenverfahren nennt. Bei diesem Verfahren wird berechnet in welche “Richtung” (größer oder kleiner) man die Parameterwerte verändern müsste, damit das Ergebnis näher an dem gewünschten Ergebnis liegt. Jetzt verändert man die Parameterwerte einen kleinen Schritt in die jeweilige Richtung (visualisiert über die grünen Pfeile) und erhält eine etwas bessere Ausgabe von 35%.

Das eben beschriebene Verfahren ist ein einzelner Trainingsschritt im Trainingsprozess. Dieser Schritt wird anschließend mit weiteren Bildern aus dem Trainingsdatensatz wiederholt. So werden die Parameterwerte stückweise immer weiter angepasst.
Während dem Trainingsprozess wird dem Modell hintereinander jedes Bild aus den Trainingsdaten als Eingabe gegeben und folgende Schritte ausgeführt:
- Die Ausgabe des Modells wird verglichen mit der gewünschten Ausgabe.
- Über das Gradientenverfahren erhält man für dieses Eingabebild eine “Richtung” in die man die Modell-Parameter ändern kann, um die Ausgabe zu verbessern.
- Die Modell-Parameter werden um einen Schritt in diese “Richtung” verändert.
Nachdem alle Bilder des Trainingsdatensatzes diesen Prozess durchlaufen haben, glaubst du, dass das Modell jetzt funktioniert?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Nachdem alle Bilder aus dem Trainingsdatensatz einmal für das Training genutzt wurden, kann es immer noch sein, dass das Modell nicht so funktioniert, wie wir uns es wünschen. Oft nutzt man deshalb dieselben Trainingsdaten erneut in mehreren Durchläufen, bis sich die Parameterwerte stabilisieren und bei neuen Durchläufen nicht mehr stark verändern.
Aber auch nach mehreren Durchläufen kann es sein, dass das Modell nicht wie gewünscht funktioniert. Das kann eine Vielzahl an Gründen haben. Zum Beispiel kann es sein, dass die Modellstruktur (also die Berechnungsformel) nicht genug Freiraum bietet, diese Aufgabe lösen zu können. Dann könnte man es mit einer anderen Modellstruktur erneut versuchen. Neben dieser Ursache gibt es aber noch eine Vielzahl an anderen Gründen, auf die wir nicht im Detail eingehen.
Nehmen wir an, dass wir nach dem Training sehen, dass unser Modell die Trainingsdaten richtig klassifizieren kann. Allerdings wollen wir von dem Modell Klassifizierungen für neue und noch ungesehene Winkel. Glaubst du, dass das Modell auch für solche Winkel eine richtige Einordnung liefert? Wie könnte man das überprüfen?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Es kann passieren, dass das Modell jetzt auch neue und ungesehene Bilder richtig einordnet. Das würde bedeuten, es hat gelernt, worauf es im Bild achten muss und wie man spitze von stumpfen Winkeln unterscheiden kann. Allerdings kann es auch passieren, dass neue Bilder nicht richtig eingeordnet werden. Statt auf allgemeine Merkmale über verschiedene Bilder hinweg, kann das Modell zum Beispiel auch die Trainingsdaten sozusagen “auswendig gelernt” haben. Das bezeichnet man als Overfitting.
Um zu überprüfen, ob das Modell etwas lernt, was auch für neue Eingaben nützlich ist, nutzt man einen weiteren Datensatz, den man Testdaten nennen. Genauso wie bei den Trainingsdaten, sind diese Bilder ebenfalls schon bewertet, werden allerdings nicht für den Trainingsprozess genutzt. Sie dienen dazu, das Verhalten des Modells am Ende zu testen.
Schafft es das Modell Bilder aus den Testdaten richtig einzuordnen, wissen wir, das Modell hat im Trainingsprozess etwas gelernt, mit dem auch neue, bisher ungesehene Bilder von Winkeln eingeordnet werden können. Kann es dagegen nur die Trainingsdaten richtig bewerten und versagt bei den Testdaten, hat es vermutlich lediglich die Trainingsdaten “auswendig gelernt”, aber nicht “verstanden” auf welche Eigenschaften es achten soll.
Trainiere selbst ein Modell
Jetzt kommen wir zum praktischen Teil und werden ein eigenes Modell trainieren und testen. Dabei werden wir tiefgreifender verstehen, wie maschinelles Lernen funktioniert und welche Probleme beim Training auftreten können. Darüber hinaus hilft uns dieser Einblick auch dabei besser abschätzen zu können, wie wir KI sinnvoll einsetzen können.
Unser Modell trainieren wir auf der Webseite Teachable Machine. Teachable Machine vereinfacht den Prozess ein eigenes Modell zu trainieren für uns deutlich: Viele technische Details sind verborgen, es ist keine Programmiererfahrung notwendig und die Menge an Trainingsdaten ist geringer, da bereits ein vortrainiertes Modell zugrunde liegt.
Teachable Machine eignet sich nicht für jede erdenkliche Entwicklung mit maschinellem Lernen. In der Praxis wird häufig in einer Programmiersprache wie Python und mithilfe von Software-Libraries wie beispielsweise TensorFlow gearbeitet. Trotzdem ist Teachable Machine ein nützliches Werkzeug, um maschinelles Lernen zu verstehen und die trainierten Modelle können anschließend heruntergeladen und für Projekte genutzt werden.
Teachable Machine nutzen
Wir starten mit einem vorgegebenen Modell, damit wir uns schrittweise mit Teachable Machine vertraut machen können.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Gehe auf die Teachable Machine Webseite, klicke auf Bestehendes Projekt aus einer Datei öffnen und wähle dort das Beispielprojekt aus.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Es sollte jetzt folgende Oberfläche sichtbar sein:

Klicke auf Modell trainieren und bleibe so lange im selben Browser-Tab, bis das Modell fertig trainiert ist.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Erlaube der Webseite, deine Kamera zu benutzen, wenn danach gefragt wird. Eventuell wirst du aber auch nicht gefragt.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Jetzt solltest du das Bild deiner Webcam sehen.
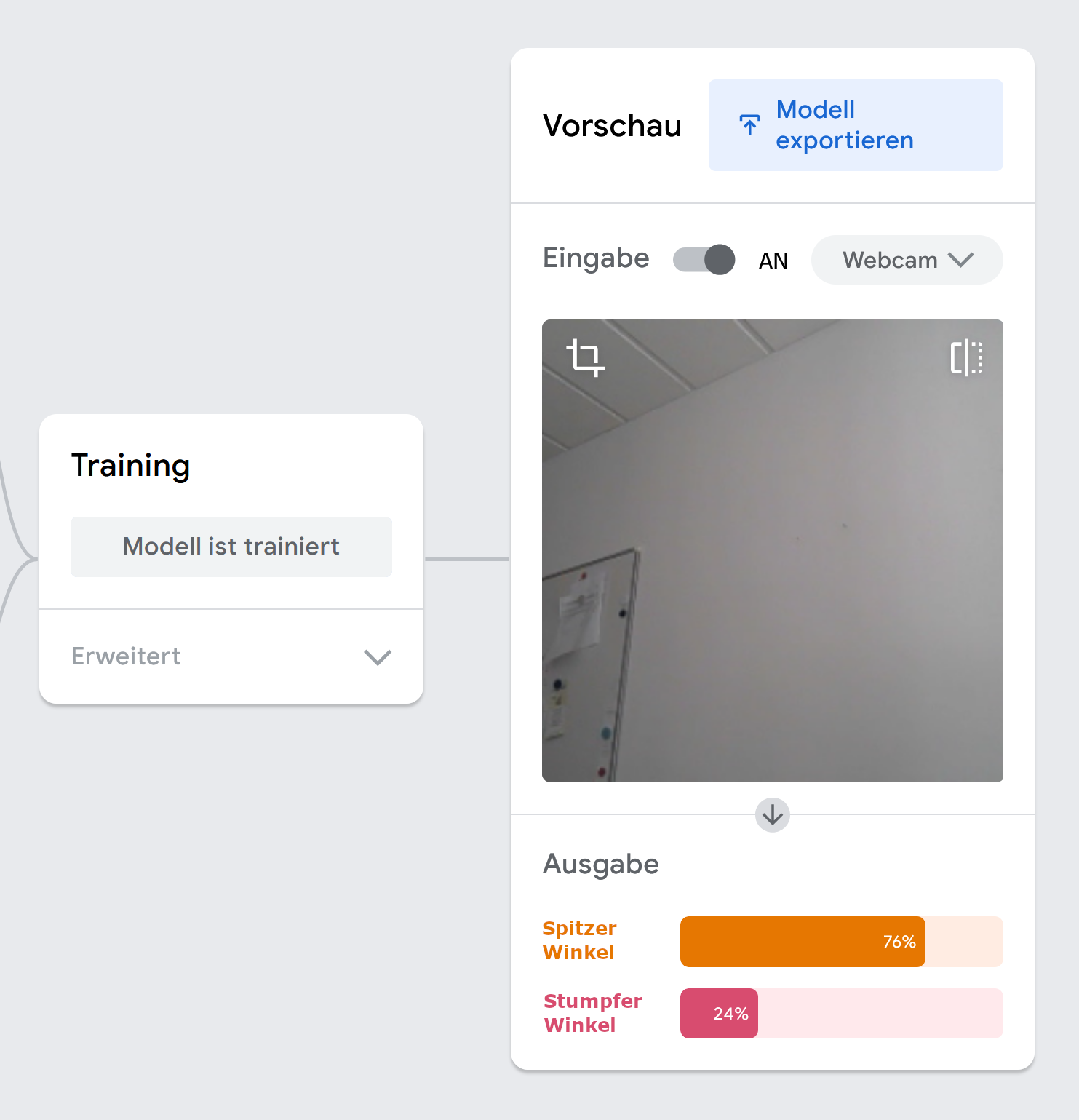
Dieses Modell versucht einen gezeichneten Winkel zu den spitzen und stumpfen Winkeln zuzuordnen. Auf der linken Seite siehst du Beispiele für solche gezeichneten Winkel.
Nimm dir ein Stück Papier, zeichne ein paar Winkel darauf und halte sie in die Webcam. Unter dem Bild der Webcam siehst du das Ergebnis.
Wichtig: Achte dabei darauf, dass kein Hintergrund, sondern nur Papier auf dem Bild zu sehen ist.
Was fällt dir auf?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Das Modell sollte in der Lage gewesen sein, einige Winkel richtig einzuordnen. Allerdings ist sich das Modell vermutlich bei einigen Eingaben unsicher gewesen. Vielleicht hast du es auch geschafft, eine Zeichnung zu erstellen, die zuverlässig falsch eingeordnet wurde.
Es ist außerdem auffällig, dass das Modell permanent eine Ausgabe liefert, egal ob man gerade eine Zeichnung präsentiert oder nur der Hintergrund der Webcam zu sehen ist. Es hilft, sich in Erinnerung zu rufen, dass das Modell für jedes Eingabebild eine Formel berechnet. Diese wird in diesem Fall mehrmals pro Sekunde berechnet, egal was auf dem Bild zu sehen ist.
Auf der linken Seite siehst du die zwei Kategorien (hier Klassen genannt), die wir unterscheiden: Die spitzen und die stumpfen Winkel. Außerdem siehst du hier auch die jeweiligen Trainingsdaten, mit denen das Modell trainiert wurde.
Versuche einen Winkel zu zeichnen, bei dem die KI nicht klar unterscheiden kann, ob es sich um einen stumpfen oder spitzen Winkel handelt. Du kannst dir dafür die Trainingsdaten genauer anschauen und überlegen, welche Form “zwischen” einem spitzen und einem stumpfen Winkel liegen könnte.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Vermutlich ist dir hier ein rechter Winkel (90°) eingefallen. Dieser liegt genau am Übergang zwischen spitzen und stumpfen Winkeln. Bei unseren Tests war sich das Modell unsicher, mit einer leichten Tendenz zu einem stumpfen Winkel. Hier funktioniert das Modell also noch nicht korrekt.
Vielleicht ist dir in den Trainingsdaten aufgefallen, dass ein Schenkel des Winkels immer von der Mitte des Bildes horizontal nach rechts geht. Der andere Schenkel geht immer von der Mitte nach oben, allerdings mit unterschiedlichen Richtungen. Aber ist es wichtig, dass beim Testen des Modells diese Eigenschaften auch immer erfüllt sind? Könnte man die Zeichnung auch beliebig drehen, mit demselben Ergebnis?
Nimm dir einen deiner gezeichneten Winkel, die richtig bewertet wurden, halte ihn in die Webcam und drehe ihn. Was fällt dir auf?
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Vermutlich hast du gesehen, dass das Modell oft auch damit zurecht kommt, wenn der Winkel nicht genauso ausgerichtet ist, wie in den Trainingsdaten. Vielleicht hast du aber auch bemerken können, dass bei bestimmten Drehungen der Zeichnung, die Bewertung unsicher wird oder sogar umschlägt. Scheinbar achtet das Modell hier auf etwas, was wir nicht beabsichtigt haben.
Es wäre hilfreich, wenn man einen Blick ins Modell werfen könnte, um herauszufinden, worauf genau das Modell achtet. Das Problem ist nur, dass wir dort keine klaren Regeln vorfinden, sondern eine lange Berechnungsformel mit zahlreichen Parametern, die für uns Menschen größtenteils nicht erklärt, worauf die KI achtet. Das bezeichnet man oft auch als Problem der Erklärbarkeit bei datenbasierter KI. Wissensbasierte KI dagegen arbeitet mit Wissen, welches vom Menschen kommt und ist dadurch deutlich leichter zu verstehen.
Auch in unseren Tests haben wir zum Beispiel folgendes entdeckt:
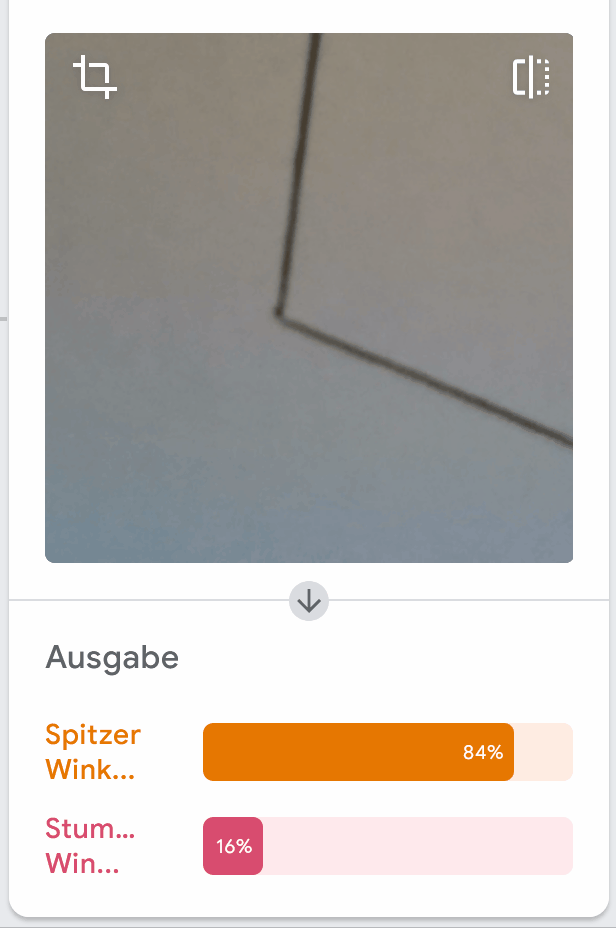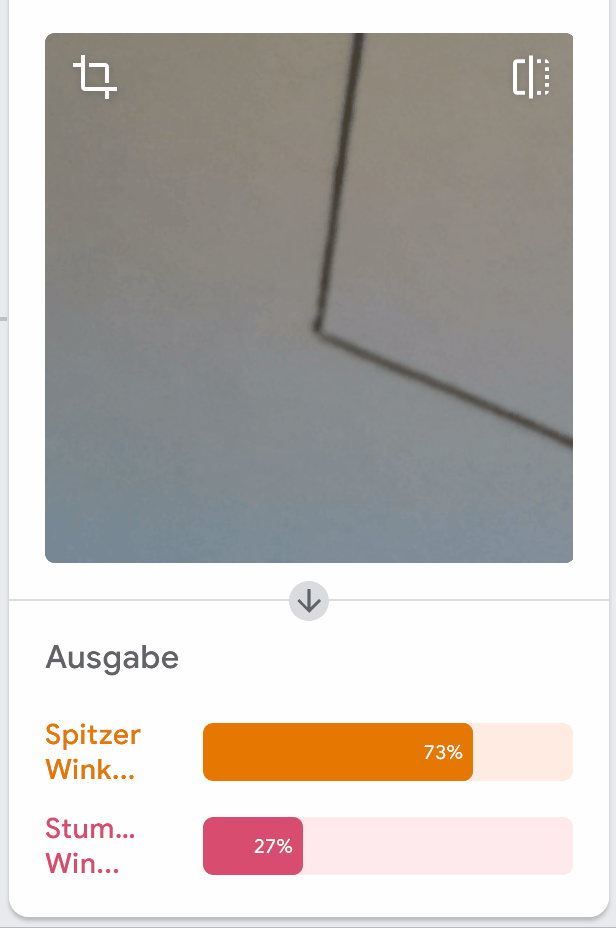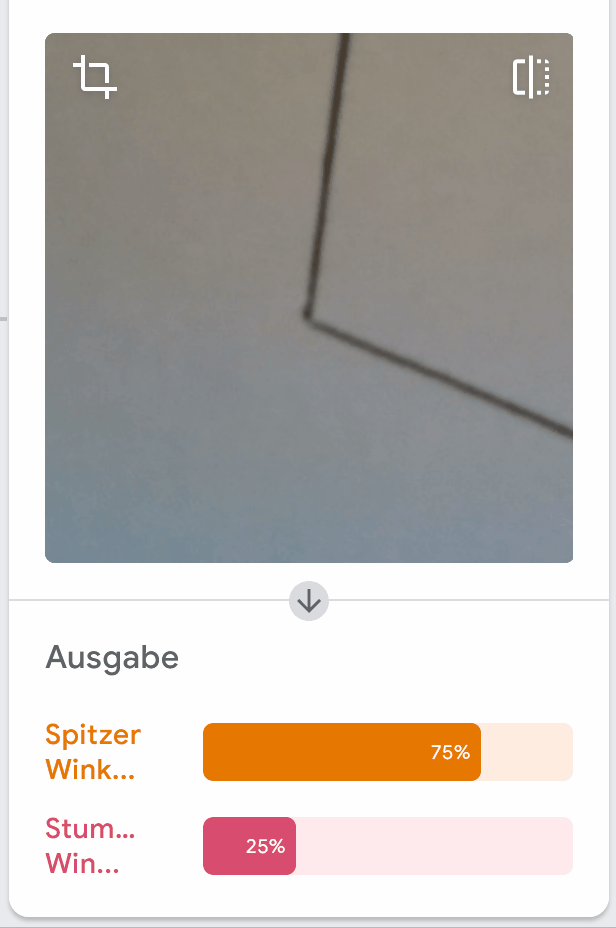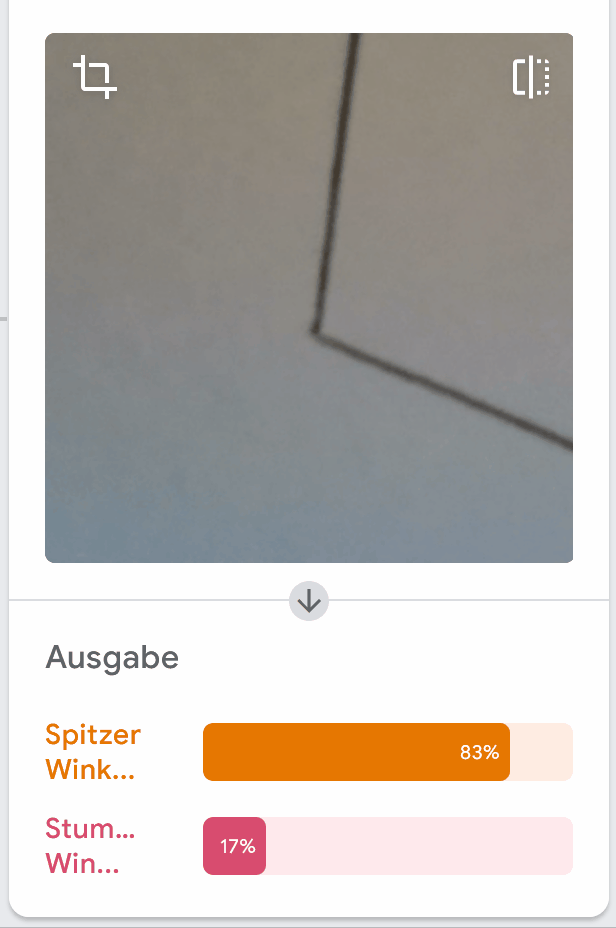
Welche Eigenschaft im Bild könnte das Modell fälschlicherweise annehmen lassen, dass es sich um einen spitzen Winkel handelt?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Es hilft, sich in Erinnerung zu rufen, dass das Modell allein aus den Daten gelernt hat, was es tun soll. Ob es auf eine Eigenschaft in den Bildern achtet, die wir beabsichtigen, ist nicht sicher.
Wenn wir einen Blick auf die Trainingsdaten werfen, sehen wir, dass es noch andere Merkmale gibt, nach denen man unterscheiden könnte.

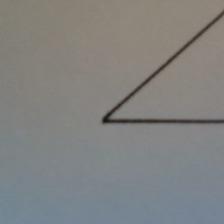




In allen Beispielen von spitzen Winkeln zeigt einer der Schenkel nach rechts oben. Im Gegensatz dazu zeigt der Schenkel bei stumpfen Winkeln immer nach links oben. Im Trainingsprozess wäre das also auch ein eindeutiges Merkmal, auf welches das Modell lernen könnte zu achten.
Die falsche Bewertung, die wir oben gezeigt haben, könnte aus diesem Grund entstanden sein, denn hier zeigt auch einer der Schenkel nach rechts oben, was als Merkmal für einen spitzen Winkel verstanden werden kann.
Aus dieser Beobachtung wollen wir uns mitnehmen:
Ein Modell muss nach dem Training mit möglichst vielfältigen Eingaben getestet werden. Nur dadurch stellt sich heraus, ob das Modell auch auf die Merkmale achtet, die man beabsichtigt hat.
Modell verbessern
Nachdem wir jetzt mit Teachable Machines vertraut sind und gesehen haben, woran das vorgegebene Modell noch scheitert, wollen wir in diesem Abschnitt ein neues Modell trainieren, welches besser klassifiziert.
Im vorherigen Modell konnte man sehen, dass Winkel nahe an 90°, also nahe am Übergang von stumpf zu spitz entweder nicht richtig oder sehr unsicher klassifiziert wurden. In unserem neuen Modell wollen wir versuchen, diese Grenze mehr zu beachten.
Wie könnten wir die Trainingsdaten dafür anpassen?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Indem wir sicherstellen, dass es mehrere Trainingsbilder gibt, deren Winkel nahe an 90° ist, können wir über die Daten dem Modell genauer zeigen, dass bei 90° der Übergang zwischen stumpfen und spitzen Winkeln ist.
Außerdem haben wir im vorherigen Modell bemerkt, dass derselbe Winkel unterschiedlich klassifiziert wird, je nachdem, wie er ausgerichtet ist. Unsere Vermutung war, dass das Modell gelernt hat nur auf die Ausrichtung des oberen Schenkels (nach rechts oder links oben) zu achten, statt auf den Winkel zwischen den Schenkeln.
Wie könnten wir die Trainingsdaten dafür anpassen?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Wir könnten jeden unserer gezeichneten Winkel mehrmals als Trainingsbild verwenden, mit jeweils unterschiedlicher Ausrichtung. Damit würden wir über die Daten dem Modell zeigen, dass die Ausrichtung der Schenkel nicht von Bedeutung sein soll.
Nachdem wir jetzt wissen, worauf wir beim neuen Modell achten wollen, starten wir ein neues Projekt auf Teachable Machine:
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Benenne die zwei Klassen auf der linken Seite um in Stumpfer Winkel und Spitzer Winkel indem du auf den Stift neben dem Namen klickst.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Alle weiteren Einstellungen kannst du so belassen und wir werden als Nächstes ein paar Trainingsdaten hinzufügen. Zuerst fügen wir ein Bild zur Kategorie Stumpfer Winkel hinzu.
Zeichen zunächst einen stumpfen Winkel.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Schritt 1
Klicke im Block Stumpfer Winkel auf Webcam.
Beim ersten Bild: Eventuell wirst du von deinem Browser beim ersten Mal gefragt, ob die Webcam benutzt werden darf. Stimme dem zu.
Falls ein anderes Programm oder ein anderer Browser-Tab gerade deine Webcam benutzt, kann es zu Problemen kommen. Oft hilft es dann alle diese anderen Anwendungen oder Browser-Tabs zu schließen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Jetzt solltest du wieder das aktuelle Bild deiner Webcam sehen.
Schritt 2
Halte deine Zeichnung in die Webcam und achte dabei darauf, dass der Scheitelpunkt des Winkels ungefähr in der Mitte vom Bild ist, dass die Schenkel des Winkels bis zum Rand gehen und ansonsten keine anderen Dinge sichtbar sind außer weißes Papier. Eventuell kannst du nicht beliebig nahe an deine Webcam gehen, da sonst das Bild unscharf wird. In dem Fall einfach etwas weiter entfernen.
Sobald du eine gute Distanz gefunden hast, klicke Zum Aufnehmen halten.
Drehe den Winkel beliebig und wiederhole diesen Schritt noch zwei mal.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Auf der rechten Seite sollten mehrere Bilder erscheinen von deiner Zeichnung.
Schritt 3
Lösche Bilder, die doppelt vorkommen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Damit haben wir unsere ersten Trainingsbilder hinzugefügt.
Zeichen jetzt 5 weitere stumpfe und 6 spitze Winkel und wiederhole die Schritte 1-3 für jeden.
Denk daran, dass drei spitze und drei stumpfe Winkel nahe an 90° liegen sollten, also zum Beispiel 75°, 80°, 85° & 95°, 100°, 105°. Denke außerdem daran, jeden gezeichneten Winkel 3 mal in unterschiedlichen Ausrichtungen in die Trainingsdaten aufzunehmen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Du solltest jetzt in beiden Klassen jeweils 18 Bilder haben. Jeweils 6 unterschiedliche Winkel, die in 3 unterschiedlichen Ausrichtungen aufgenommen wurden.
Klicke jetzt auf Modell trainieren und warte bis das Training abgeschlossen ist.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Das war es, jetzt ist dein Modell trainiert. Aktivierst du auf der rechten Seite die Webcam, kannst du das Ergebnis der Berechnung im Modell für das aktuelle Kamerabild sehen.
Wie könntest du jetzt testen, ob das Modell funktioniert?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Um herauszufinden, ob das Modell funktioniert, reicht es nicht, die Zeichnungen zu testen, die bereits in den Trainingsdaten verwendet wurden. Das Modell wurde auf Grundlage dieser Bilder erstellt und bekam die “korrekte” Klasse gleich mit dazu. Um das Modell zu testen, zeichnen wir also neue Winkel (die Testdaten), die sich von den Trainingsdaten unterscheiden. Werden diese auch richtig eingeordnet, bedeutet das, das Modell hat nicht nur die Trainingsdaten auswendig gelernt, sondern hat gelernt bestimmte Eigenschaften in den Zeichnungen zu erkennen, die auf spitze oder stumpfe Winkel hindeuten.
Bilder, mit denen das Modell getestet wird, dürfen nicht in den Trainingsdaten vorkommen.
Zeichne jetzt ein paar neue Winkel und teste das Modell. Drehe dabei die Winkel, um zu überprüfen, ob das Modell auch mit jeder Ausrichtung zurecht kommt.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Vermutlich ist dein Modell in der Lage einige Winkel richtig einzuordnen und ist vielleicht sogar besser als unser Anfangsmodell. Allerdings wirst du vereinzelnd immer noch Winkel in besonderen Ausrichtungen finden, die zu einer unsicheren oder falschen Einordnung führen. Um auch diese Fälle abzudecken sind vermutlich deutlich mehr Trainingsdaten notwendig. Ebenso kann es allerdings auch sein, dass du beim Erstellen der Trainingsdaten unbemerkt ein ungewünschtes Merkmal hinterlassen hast, worauf das Modell statt dem Winkel achten könnte. Zum Beispiel könnten spitze Winkel (im Gegensatz zu den stumpfen Winkeln) nicht ganz mittig zentriert sein und das Modell entscheidet auf dieser Grundlage.
Dir ist vermutlich aufgefallen, dass es keine triviale Aufgabe ist, das Modell zu trainieren. Du hast gesehen, wie wichtig das Testen ist. Das gilt auch für andere KI-Entwicklungen, die maschinelles Lernen benutzen:
Was das Modell aus den Daten gelernt hat zu erkennen, muss durch anschließendes Testen herausgefunden werden. Es kann passieren, dass das Modell auf Eigenschaften in der Eingabe achtet, die man nicht beabsichtigt hat.
Außerdem hast du gesehen, dass die KI keinesfalls selbstständig lernt, das Richtige zu tun. Wir mussten an vielen Stellen testen und die Trainingsdaten geschickt auswählen. Wir wollen uns merken:
Eine wichtige und oft umfangreiche Aufgabe beim maschinellen Lernen ist die Auswahl und Verarbeitung von Daten für das Training und Testen des Modells. Für diese Aufgabe wird meistens ein Mensch benötigt.
Wie sieht “reales” maschinelles Lernen aus?
Teachable Machine ist mit eine der einfachsten Methoden ein Modell zu trainieren und hat sich daher gut für diese Lernmaterialien geeignet. Allerdings findet maschinelles Lernen in den meisten Fällen über andere Wege statt. Diese bieten mehr Flexibilität, sind dadurch aber komplizierter und erfordern Kenntnisse im Programmieren.
Die Menge an Trainingsdaten für unser Modell war sehr gering im Vergleich zu “realen” Verfahren. Das war möglich, weil auf Teachable Machine ein bereits vortrainiertes Modell nur noch für die Klassifizierung von Winkeln spezialisiert wurde. Typischerweise ist die Anzahl an notwendigen Trainingsdaten deutlich höher.
Reale Anwendungsfälle von KI zur Bewertung von Aufgaben müssen mit deutlich mehr Vielfalt in der Eingabe umgehen können als unser Modell zur Klassifizierung von Winkeln. Unsere gezeichneten Winkel sind relativ einfach zu unterscheiden, sowohl für den Menschen als auch für eine KI: Es gibt vorwiegend nur zwei Farben (Farbe des Stifts und der weiße Hintergrund), abseits der zwei Schenkel sieht man keine weiteren Zeichnungen, die Winkel waren im Bild zentriert und viele weitere Eigenschaften haben das Training leichter gemacht. In realen Anwendungsfällen gibt es deutlich mehr Markmale in den Bildern. Das erfordert mehr Trainingsdaten, kompliziertere Modelle und mehr Aufwand ein Modell erfolgreich zu trainieren.
Das Verfahren, welches wir hier kennengelernt haben, ist also eine sehr vereinfachte Variante, aber die Bestandteile finden sich auch in anderen Verfahren bei der Entwicklung mit maschinellem Lernen wieder. Uns hat es geholfen, den Prozess und die wichtigen Schritte und Eigenschaften zu verstehen.
Wir sind nicht genauer auf die interne Struktur der Modelle eingegangen oder wie das Gradientenverfahren funktioniert. Zudem wurden auf Teachable Machine viele technische Details verborgen. Für ein grundlegendes Verständnis von KI sind diese Informationen nicht unbedingt notwendig. Falls es dich allerdings interessiert, können wir die Videoserie zu Neural Networks von 3Blue1Brown (mit deutschen Untertiteln) empfehlen. Für die restlichen Kapitel in diesem Kurs sind diese Inhalte allerdings nicht notwendig.
Im nächsten Kapitel beschäftigen wir uns mit der Frage: Was kann KI und was kann KI nicht? Dabei werden wir auch über andere Formen von maschinellem Lernen sprechen und vielfältige Anwendungen von KI im Bereich Lehren & Lernen kennenlernen.