
Anfang
In diesem Kapitel wollen wir uns zwei wichtige Eigenschaften von datenbasierter KI anschauen: Die Erklärbarkeit und den Bias. Beide stellen oft ein Problem bei der Entwicklung und dem Einsatz von KI dar. Wir werden sowohl auf die Probleme als auch auf Lösungsmöglichkeiten eingehen.
Datenbasierte KI (Wiederholung)
Hierunter fallen alle Formen von KI, die aus Daten gelernt haben. Das Wissen innerhalb der KI wurde also nicht vom Menschen bereitgestellt, sondern aus Daten gelernt.
Im Weiteren werden wir uns mit zwei Fragen beschäftigen:
" Können wir uns erklärbar machen, worauf eine datenbasierte KI achtet? "
" Ist datenbasierte KI objektiv, unvoreingenommen, ...? "
Erklärbarkeit
Wir haben im Kapitel 2 das Verfahren überwachtes maschinelles Lernen kennengelernt und dort bereits das Problem der Erklärbarkeit entdeckt:
Nachdem wir unser Modell zur Bewertung von Leberflecken trainiert hatten, konnte die KI gutartige von bösartigen Leberflecken anhand ihrer Form unterscheiden. Allerdings wussten wir nicht, nach welchen Regeln das Modell entscheidet oder auf welche Eigenschaften im Bild (Größe, Form, Farben, …) geachtet wird. Würde man einen Blick innerhalb des trainierten Modells werfen, würde man dort eine lange Berechnungsformel finden. Darin ist das Wissen repräsentiert, welches sich das Modell im Verlauf des Trainings aus den Trainingsdaten angeeignet hat. Die Berechnung ist für einen Computer klar verständlich, allerdings nicht für einen Menschen. Über diesen Weg ist es nur sehr begrenzt möglich zu erklären, wie das Modell diese Aufgabe bewältigt.
Bei datenbasierter KI liegt das Wissen oft in einer Form vor, die für den Menschen größtenteils unverständlich ist. Es kann also durch Anschauen des Modells nicht erklärt werden, wie das Modell funktioniert.
Dieses Problem wird bezeichnet als Black-Box-Charakteristik oder Problem der Erklärbarkeit.
Bei wissensbasierter KI ist es im Vergleich oft leichter nachzuvollziehen, wie sie intern funktioniert. Das liegt daran, dass bei dieser Form das Wissen vom Menschen und nicht aus Daten kommt, zum Beispiel in Form von Regeln. Dadurch liegt das Wissen in einer für den Menschen verständlicheren Form vor.
Obwohl wir durch Anschauen bei datenbasierter KI oft nicht erklären können, wie das Modell funktioniert oder worauf es achtet, können wir durch Testen Einblicke bekommen, ob und wie das Modell funktioniert.
In Kapitel 2 bei der Bewertung von Leberflecken haben wir nach dem Training des Modells anschließend neue Leberflecke gezeichnet und damit das Modell getestet. Indem wir absichtlich bestimmte Eigenschaften variiert haben, wie zum Beispiel die Größe des Leberflecks, konnten wir herausfinden, ob das Modell diese Eigenschaft bei der Bewertung beachtet.
Durch Testen und andere Methoden kann man sich zum Teil erklärbar machen, worauf datenbasierte KI achtet bzw. wie sie funktioniert.
Das Testen ist allerdings oft keine triviale Aufgabe. Manchmal funktioniert das Modell für eine bestimmte Eingabe nicht richtig und es ist nicht klar, warum. In dem Fall weiß man dann eventuell auch nicht, was man als Nächstes testen sollte.
Zudem ist es oft nicht möglich, umfangreich zu testen. Das liegt einerseits daran, dass die Anzahl der möglichen Eingaben zu groß sein kann. Andererseits müssen die Ausgaben des Modells beim Testen meistens von einem Menschen überprüft werden, denn oft entscheiden wir ob, das Ergebnis korrekt ist oder nicht.
Stellen wir uns vor, wir würden jede mögliche Eingabe für unser Modell zur Bewertung von Leberflecken testen wollen. Wenn die Bilder eine Auflösung von 200x200 (also insgesamt 40.000) Pixeln haben und jeder Pixel 100 Farbwerte annehmen kann, dann gibt es “100 hoch 40.000” mögliche Eingaben. Die Zahl wäre dann eine 1 mit 80.000 Nullen danach.
Die Erklärbarkeit ist eine Eigenschaft, mit der man sicherstellen kann, dass ein System korrekt funktioniert. Schauen wir uns ein Beispiel dazu an:
Angenommen, wir nutzen eine wissensbasierte KI, die das Resultat eines Tests als Eingabe bekommt und uns die empfohlene Dosis für die Verabreichung eines Medikaments zurückgibt. Wir schauen in die KI hinein, wie sie intern funktioniert und finden eine einfache Regel, die die SoftwareentwicklerInnen geschrieben haben: “Wenn der Testwert höher als 100 ist, dann empfehle eine Dosis von 2mg. Ansonsten 1 mg.” Die Entscheidung der KI ist erklärbar und wir können uns sicher sein, dass nie eine Dosis von 10mg empfohlen werden wird. Dies ist zwar ein stark vereinfachtes Beispiel, aber auch reale Systeme können auf diese Art und Weise auf Korrektheit überprüft werden. Bei einer datenbasierten KI funktionieren solche Methoden nicht, denn im Inneren finden wir eine Berechnung, die für Menschen größtenteils unverständlich ist.
Bei datenbasierter KI müssen andere Methoden verwendet werden, um zu testen, ob das System korrekt funktioniert.
Im Bereich Gesundheit & Pflege geht es primär um das Wohlergehen von Menschen. Deshalb spielt die Erklärbarkeit von KI eine besondere Rolle im Vergleich zu anderen Bereichen.
Die Erklärbarkeit von KI ist in den letzten Jahren zu einem starken Forschungsfeld geworden. Es gibt verschiedene Ansätze, wie man sich die Entscheidungen von datenbasierter KI verständlich machen kann.
Eine Möglichkeit, die wir auch bei unserer KI zur Bewertung von Leberflecken einsetzen könnten, nennt sich Integrated Gradients. Hier wird visualisiert, welche Bereiche im Bild vom Leberfleck einen starken Einfluss auf die Bewertung haben. Dadurch kann man als KI-EntwicklerIn sehen, ob das Modell eventuell auf Aspekte im Bild achtet, die man nicht beabsichtigt hat.
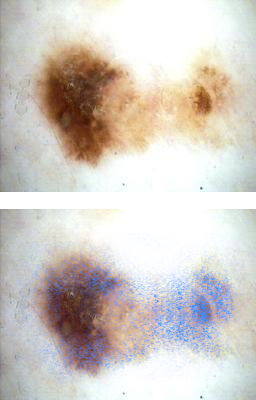
Es gibt noch viele weitere Ansätze, mit denen man die Erklärbarkeit von datenbasierter KI verbessern kann und neue Methoden werden aktuell erforscht und entwickelt. Für einen zukünftigen Einsatz von KI im Bereich Gesundheit & Pflege wird das ein wichtiger Schritt sein, denn wir wollen Systeme, die korrekt funktionieren und nachvollziehbare Entscheidungen treffen.
Bedeutung der Trainingsdaten
Beim überwachten Lernen gibt der Trainingsdatensatz vor, welche Ausgaben das Modell haben soll für bestimmte Eingaben. Als wir das Modell zur Bewertung von Leberflecken trainiert haben, haben die Trainingsdaten dem Modell sozusagen Beispiele gezeigt für “bedenkliche” und “unbedenkliche” Leberflecke. Aus diesen Beispielen wurden im Trainingsprozess dann die Modell-Parameterwerte bestimmt, die dieses Eingabe-Ausgabe-Verhalten versuchen nachzustellen. Die Wahl eines geeigneten Trainingsdatensatzes ist also sehr wichtig.
Was glaubst du, würde passieren, wenn sich in unseren Trainingsdaten ein Fehler einschleicht? Zum Beispiel ein Leberfleck, der falsch bewertet wurde.
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Es ist anzunehmen, dass wir in realen Datensätzen immer mal wieder einen Fehler haben werden. Enthält der Datensatz allerdings etlichen tausend Bildern und ist darin nur eine falsche Bewertung, wird der Fehler vermutlich in der Menge untergehen und keinen großen Einfluss auf das Modell haben. Die Modell-Parameterwerte werden zwar einmal in “Richtung” des Fehlers angepasst, aber anschließend wieder in die korrekte “Richtung” angepasst. Je größer allerdings der Anteil der Fehler in den Trainingsdaten ist, desto mehr Einfluss werden diese Fehler haben.
Enthalten die Trainingsdaten Fehler, wird auch das trainierte Modell versuchen, diese Fehler zu reproduzieren.
Ein geeigneter Trainingsdatensatz sollte nicht nur fehlerfrei sein. Er sollte außerdem ausreichend Vielfalt enthalten, um später mit vielfältigen Eingaben umgehen zu können. Enthalten unsere Trainingsdaten zum Beispiel nur Bilder von Leberflecken, die eine scharfe Begrenzungslinie haben, kann es gut sein, dass das trainierte Modell nicht in der Lage sein wird, mit unscharfen Leberflecken umzugehen.
Die Trainingsdaten sollten ein möglichst reales Spektrum an Eingabedaten abdecken, die anschließend beim Einsatz des trainierten Modells auftreten könnten.
Aus diesem Abschnitt wollen wir uns Folgendes mitnehmen:
Die Trainingsdaten haben eine hohe Bedeutung für die letztendlichen Fähigkeiten des trainierten Modells. Sie drücken aus, welches Verhalten wir uns von der KI wünschen.
Bei der Wahl eines geeigneten Trainingsdatensatzes können eine Vielzahl an Problemen auftreten, die zu einem unerwünschten Verhalten des Modells führen. Wegen des Problems der Erklärbarkeit, sind diese Probleme teilweise auch nur schwer zu erkennen. Schauen wir uns jetzt eine Art von Problemen mit dem Trainingsdatensatz an, welche oft nicht leicht zu erkennen sind: Bias in den Trainingsdaten
Bias in den Trainingsdaten
Bias in den Trainingsdaten kann dazu führen, dass sich das trainierte Modell auf eine unerwünschte Weise verhält. Beim Bias geht es weniger um einzelne Daten, sondern mehr um den gesamten Trainingsdatensatz. Schauen wir uns gleich zu Anfang ein Beispiel an, welches das Problem verdeutlicht:
Wir haben ein Modell trainiert zur Bewertung von Leberflecken auf Teachable Machine. Nach etwas Testen stellen wir allerdings fest, dass das Modell in Ausnahmefällen eine komplett falsche Bewertung abliefert, obwohl es in den meisten Fällen richtig bewertet. Schauen wir uns das Modell genauer an.
Lade dir das Teachable Machine Projekte herunter und öffne es auf der Teachable Machine Webseite.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
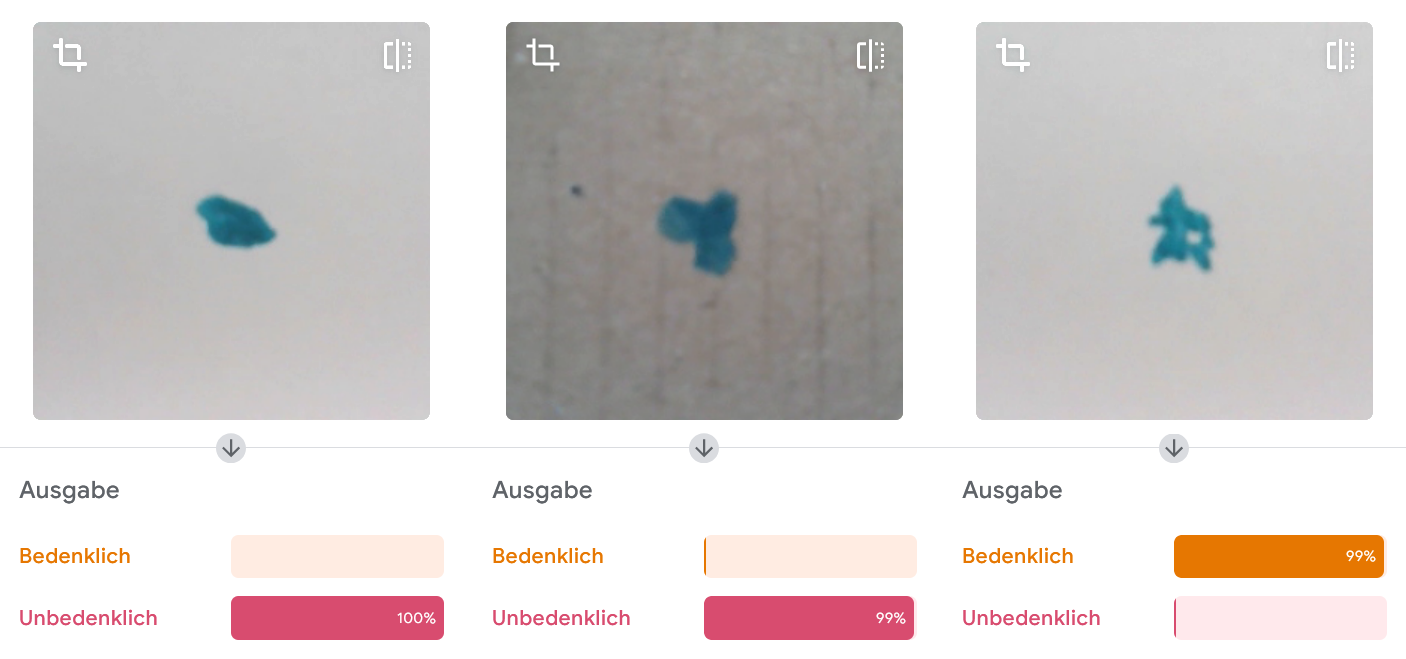
Unsere Tests zeigen uns, dass das Modell für Bilder wie diese mit sehr hoher Sicherheit richtig liegt:
Allerdings liegt das Modell bei einzelnen Beispielen komplett falsch:
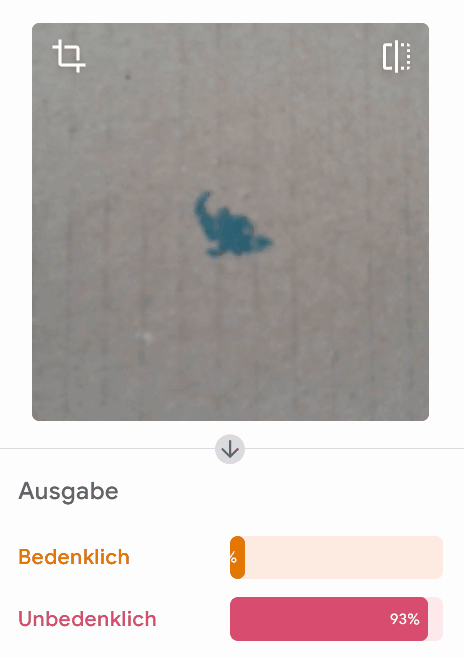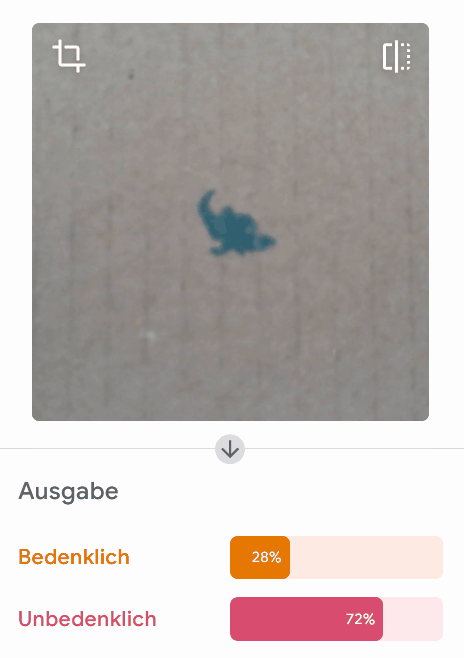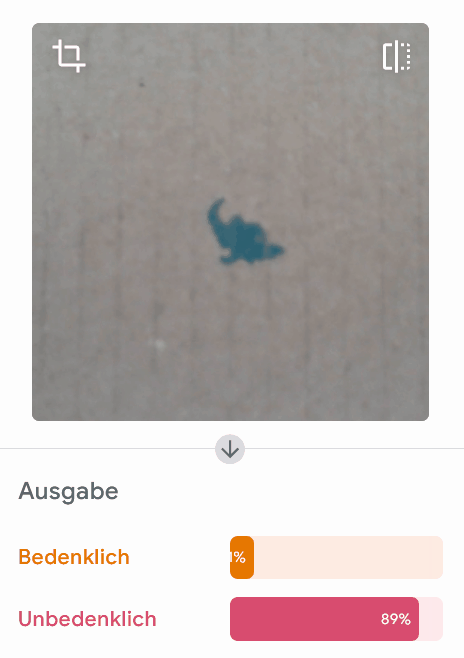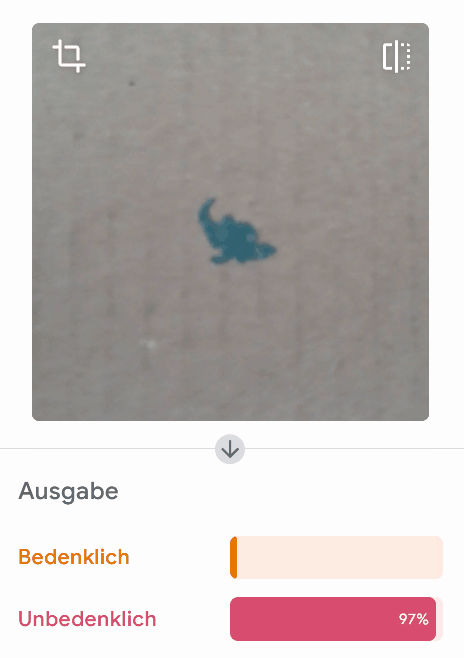
Wirf einen Blick in die Trainingsdaten! Woran könnte es liegen, dass dieses Modell in einzelnen Fällen komplett falsch bewertet? Worauf könnte das Modell achten?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Zunächst einmal sehen wir, dass es doppelt so viele Beispiele der Klasse “unbedenklich” gibt als “bedenkliche” Beispiele. Das kann dazu führen, dass dieses Modell eher dazu tendiert, Leberflecke als “unbedenklich” einzustufen, da es während dem Training öfter in diese “Richtung” angepasst wurde.
Des Weiteren kann man erkennen, dass es in den Trainingsdaten zwei verschiedene Hintergrundfarben gibt: Eine dunklere (Karton) und eine hellere (weißes Papier). Sowohl die Klasse “Bedenklich” als auch “Unbedenklich” haben jeweils 5 Bilder auf hellem Hintergrund. Beim dunkleren Hintergrund finden wir allerdings nur 2 Bilder bei “bedenklich” und 9 Bilder bei “unbedenklich”.
Welchen Effekt könnte diese ungleichmäßige Verteilung haben?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Zunächst einmal könnte man sich gut vorstellen, dass lediglich zwei Beispiele auf dunklem Hintergrund zu wenig sein könnten, um das Modell zu trainieren. Das kann sein, aber da das Modell für andere Beispiele gute Ergebnisse liefert, nehmen wir an, dass es ausreicht.
Etwas anderes könnte passiert sein, was vielleicht nicht sofort auf der Hand liegt: Das Modell könnte auch die Farbe des Hintergrunds als Merkmal nutzen, um eine Bewertung zu berechnen. Indem wir dem Modell die meisten dunklen Hintergründe als “unbedenklich” zeigen, bringen wir dem Modell vielleicht bei, mehr auf den Hintergrund zu achten und damit weniger auf die Form der Leberflecke.
Wir erinnern uns, dass wir beim Training allein über die Trainingsdaten mitteilen, was gelernt werden soll.
Der Trainingsprozess weiß nicht, welches Verhalten wir uns als EntwicklerIn vom Modell wünschen und muss sich das gewünschte Verhalten “erschließen” über die Trainingsdaten.
Vielleicht hätten wir ja auch dunkle von hellen Hintergründen unterscheiden wollen und die Leberflecke sind uns gar nicht wichtig. Dann hätte das Beispielmodell auf ein wichtiges Merkmal geachtet.
In den Trainingsdaten liegt ein Bias vor, wenn Merkmale in den Trainingsdaten nicht gleichmäßig verteilt sind. Das kann dazu führen, dass das trainierte Modell auf Merkmale achtet, die wir nicht beabsichtigt haben.
Würden wir stattdessen sicherstellen, dass in beiden Klassen (“bedenklich” und “unbedenklich”) jeweils gleich viele Beispiele mit hellem/dunklen Hintergrund sind, würde das Modell vermutlich nicht mehr die Farbe des Hintergrunds für die Bewertung nutzen. Das könnte eine Möglichkeit sein, Bias in den Trainingsdaten zu reduzieren.
Stellen wir uns vor, die gezeichneten Leberflecke sind echte und die Hintergrundfarbe die Hautfarbe eines Menschen. In dem Fall würde unser Modell also bei Menschen mit dunkler Hautfarbe eine schlechtere Bewertung abliefern und sollte nur bei hellen Hauttypen genutzt werden. Das wirft allerdings natürlich Fragen auf hinsichtlich der Inklusivität der medizinischen Versorgung:
Die medizinische Versorgung sollte allen Menschen gleichermaßen zur Verfügung stehen. Medizinische Systeme sollten keine Personengruppen ausschließen.
Datenbasierte KI wird meistens mit Daten trainiert, die aus der Realität stammen. Zum Beispiel eine Sammlung von Aufnahmen von Leberflecken und der dazugehörigen Diagnose in einer medizinischen Einrichtung.
Man kann sich gut vorstellen, dass in bestimmten Regionen in Deutschland vorwiegend Menschen mit hellerer Hautfarbe in diesen Daten vorkommen. Das würde zu einem Ungleichgewicht in den Trainingsdaten führen. Zudem kann es sein, dass die Ärztinnen und Ärzte weniger Erfahrung darin haben, Leberflecke von Menschen mit dunklerer Hautfarbe richtig zu bewerten. Menschen mit dunkler Hautfarbe könnten also durchschnittlich eine schlechtere ärztliche Versorgung bekommen. All das spiegelt sich in den Daten wider. Würde man die Daten unverändert zum Trainieren eines Modells nutzen, kann das dazu führen, dass das trainierte Modell ebenfalls schlechter bewertet bei dunklen Hauttypen.
Ein Bias in Daten kann allerdings noch viel unterschwelliger vorliegen: In 2019 fand eine Studie heraus, dass ein System zur Risikoeinschätzung von PatientInnen Menschen mit dunkler Hautfarbe benachteiligt. Das System bekam als Eingabe nicht den Hauttyp, sondern andere Daten, darunter die Kosten, die bei der medizinischen Versorgung in der Vergangenheit entstanden sind. Diese waren allerdings im Durchschnitt bei Menschen mit dunkler Hautfarbe geringer als bei Menschen mit heller Hautfarbe, wenn der Gesundheitszustand gleich war. Bei der Risikoabschätzung lieferte der Algorithmus also einen niedrigeren Wert bei dunkelhäutigen Menschen und hat diese Personengruppe demzufolge bei der Auswahl benachteiligt.
Datenbasierte KI kann auch lernen, auf Merkmale zu achten, die nicht direkt in den Eingabedaten vorkommen, sondern sich über andere Daten erschließen lassen.
Wir müssen also aufpassen, wenn wir KI mit Daten aus der Realität trainieren.
Datenbasierte KI wird meistens mit Daten trainiert, die aus der Realität stammen. Enthalten diese Daten Fehler, ungleichmäßige Verteilungen oder einen Bias gegenüber bestimmten Personengruppen, wird das trainierte Modell anschließend versuchen, diese Probleme zu reproduzieren.
Eine verbreitete Vorstellung von KI ist:
" KI entscheidet objektiver, vorurteilsfreier als der Mensch. "
Wie wir gerade gesehen haben, trifft das in Fällen, bei denen KI aus realen Daten gelernt hat, nicht von Haus aus zu.
Wir als Menschen müssen uns darum kümmern, Ungleichgewichte in den Trainingsdaten zu ermitteln und bestmöglich zu beseitigen.
Das ist allerdings in der Praxis oft nicht leicht. Manchmal fehlen notwendige Daten (zum Beispiel mehr Bilder mit dunklen Hautfarben) oder das Problem der Erklärbarkeit macht es schwer für uns zu erkennen, wann eine KI auf Merkmale achtet, die wir nicht beabsichtigt haben. Zu diesen Problemen und Fragestellung wird aktuell viel erforscht und entwickelt.
Das letzte Kapitel erwartet dich! Hier beschäftigen wir uns damit, wie wir KI im Bereich Gesundheit & Pflege nutzen sollten und wollen?