Anfang
Im letzten Kapitel haben wir genauer kennengelernt, wie überwachtes maschinelles Lernen funktioniert und selbst ein eigenes Modell trainiert. Jetzt haben wir das notwendige Wissen, um genauer auf die Frage eingehen zu können:
" Was kann maschinelles Lernen? Was nicht? "
Außerdem schauen wir uns die zwei weiteren Formen von maschinellem Lernen (unüberwachtes Lernen & verstärkendes Lernen) an und gehen auf die Frage ein:
" Welche weiteren Anwendungen von KI gibt es im Bereich Gesundheit & Pflege? "
Was kann maschinelles Lernen? Was nicht?
Im letzten Kapitel haben wir gesehen, dass innerhalb vom Modell eine umfangreiche Formel berechnet wird, die aus den Eingabewerten die Ausgabewerte berechnet. Während des Trainings wurde diese Berechnung über die Modell-Parameter angepasst. Nach dem Training blieben die Parameterwerte allerdings gleich. Das bedeutet: Zeigen wir der KI zweimal hintereinander dieselbe Eingabe, werden wir auch dieselbe Ausgabe bekommen.
Eine weit verbreitete Vorstellung über KI ist:
" KI lernt kontinuierlich dazu. "
Aber ist das wirklich so? Unsere KI aus dem letzten Kapitel konnte nur während dem Training lernen. Beim Testen oder bei der regulären Benutzung der KI hat sich das Verhalten nicht verändert.
Denken wir noch einmal an unsere Bewertung von Muttermalen aus dem vorherigen Kapitel.
Glaubst du, man könnte das Verfahren so ändern, dass die KI auch nach dem Training mit jeder Eingabe weiter dazulernt? Was wäre dafür notwendig?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Ja, es ist möglich, das Verfahren so anzupassen, dass das Modell auch während der regulären Benutzung weiter trainiert wird. Allerdings benötigt man dann natürlich auch für diese neuen Bilder eine “korrekte” Bewertung in “unbedenklich” oder “bedenklich”. Ohne diese, ist es nicht klar, ob das Modell richtig bewertet hat und demzufolge, wie man die Modell-Parameter anpassen muss. In der Praxis würde das bedeuten, dass die Diagnose zuerst eindeutiger werden muss. Zum Beispiel, indem Zeit vergeht oder weitere Untersuchungen ein genaueres Ergebnis liefern. Die Diagnose zusammen mit dem ursprünglichen Bild können dann als neue Trainingsdaten genutzt werden.
Obwohl ein kontinuierliches Training möglich ist, bringt es einen Nachteil mit sich: Das Modell verändert sich kontinuierlich und müsste demzufolge regelmäßig neu getestet werden. Wir haben im letzten Kapitel herausgefunden, dass das Modell versucht Merkmale in den Trainingsdaten zu erkennen. Allerdings ist das Gelernte (die Modell-Parameter) innerhalb des Modells eine für uns unverständliche Liste an Werten, die keinen Aufschluss darüber zulässt, welche Merkmale genau beachtet werden. Deshalb müssen Modelle im Anschluss an das Training ausgiebig getestet werden. Ein Modell, welches kontinuierlich weiter dazulernt, kann also über die Zeit hinweg verändern, auf welche Merkmale geachtet wird. Beispielsweise könnte es passieren, dass eine solche KI nur Muttermale einer bestimmten Kategorie sieht und Stück für Stück verlernt, andere Kategorien von Muttermalen bewerten zu können.
Viele Anwendungen von KI lernen nicht kontinuierlich dazu, während man sie benutzt, sondern werden einmal auf Grundlage eines geeigneten Trainingsdatensatzes trainiert.
Eine weitere weit verbreitete Vorstellung ist:
" KI lernt selbstständig, ohne dass der Mensch viel tun muss. "
Der praktische Teil aus dem letzten Kapitel hat dir schon gezeigt, dass diese Vorstellung nicht ganz zutrifft. Im letzten Kapitel war es deine Aufgabe, das Modell zu testen und die Trainingsdaten zu erstellen. Es ist also keineswegs so, dass es unsere einzige Aufgabe ist, dem Modell einen beliebigen Trainingsdatensatz zu geben und der Rest passiert automatisch. Wir müssen das Modell testen, die Trainingsdaten anpassen und diesen Prozess evtl. mehrmals durchlaufen.
Unsere Experimente auf Teachable Machines haben uns zudem eine Reihe an Aufgaben erspart, die bei “realer” KI-Entwicklung anfallen. Zum Beispiel:
- Es gibt eine Vielzahl an Vorlagen für die interne Struktur innerhalb des Modells. Auch diese müssen von den KI-EntwicklerInnen ausgewählt werden und ggf. angepasst werden.
- Trainingsdaten müssen teilweise verarbeitet werden, bevor sie für das Training genutzt werden können. Beispielsweise müssen Objekte auf den Bildern in der Mitte zentriert werden.
All diese Aufgaben können nicht ohne einen Mensch mit Expertise erledigt werden.
Bei der Entwicklung mit maschinellem Lernen hat der Mensch eine Vielzahl an Aufgaben und Entscheidungen zu treffen, die nur teilweise automatisiert werden können.
Bei datenbasierter KI ist es nur schwer nachvollziehbar, auf welche Merkmale das Modell in der Eingabe achtet. Innerhalb vom Modell finden wir eine große Menge an Parameterwerten, die für uns Menschen allerdings nicht nachvollziehbar ist. Um zu überprüfen, ob das Modell richtig funtioniert, ist es notwendig, das Modell zu testen. Allerdings kann man nicht jede mögliche Eingabe testen. Das bedeutet, es kann nicht garantiert werden, dass das Modell immer richtig funktioniert. Auch nach ausgiebigem Testen mit sehr vielfältigen Eingaben kann es immer noch sein, dass das Modell auf ein Merkmal achtet, was wir nicht beabsichtigen.
Was bedeutet das speziell für den Bereich Gesundheit & Pflege?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
In Gesundheit & Pflege geht es um das Wohlergehen von Menschen. Das bedeutet, die korrekte Funktion der KI-Systeme spielt eine größere Rolle als in anderen Bereichen. Um maschinelles Lernen trotzdem in diesen Bereichen nutzen zu können, gibt es Ansätze, die darauf abzielen, datenbasierte KI “erklärbar” zu machen. Das hätte den Vorteil, dass man überprüfen könnten, ob das KI-System korrekt funktioniert, indem man nachvollziehen könnte, wie die KI ihre Entscheidungen trifft. Wir werden uns das Thema Erklärbarkeit im nächsten Kapitel genauer anschauen.
Wissensbasierte KI hat gegenüber datenbasierter KI den Vorteil, dass sie auf Grundlage von Wissen und Regeln entscheidet, die vom Menschen kommen und damit leichter von uns verstanden werden kann. Hier könnte man auch ohne Testen zuverlässige Aussagen treffen können, ob die Ausgaben korrekt sein werden.
Starke und schwache KI
Wir haben kennengelernt, wie KI mit überwachtem, maschinellem Lernen funktioniert. Vergleichen wir das mit unserem begrenzten Verständnis dafür, wie die menschliche Intelligenz funktioniert, stellen wir schnell fest:
Heutige künstliche Intelligenz funktioniert anders als die Intelligenz eines Menschen.
Zum Beispiel wird bei KI oft eine Formel berechnet oder eine Abfolge an Anweisungen ausgeführt, die sich nicht verändert. Im menschlichen Gehirn dagegen existiert ein komplexes Netzwerk aus Neuronen, in dem kontinuierlich Verbindungen verstärkt oder abgeschwächt werden.
Allerdings gibt es Bestreben in der Wissenschaft einer “menschenähnlichen” Intelligenz näher zu kommen, die stark vom Aufbau und den Abläufen im menschlichen Gehirn inspiriert sind. Damit diese zwei Formen von KI nicht verwechselt werden, wurden sie begrifflich voneinander getrennt:
Schwache KI gibt es heutzutage und jede KI, die wir aktuell nutzen, zählt zu dieser Kategorie. Die Intelligenz von schwacher KI ist in ihren Eigenschaften unterschiedlich zur menschlichen Intelligenz. Schwache KI kann nur einzelne, klar abgegrenzte Aufgaben lösen.
Starke KI ist eine ferne Zukunftsvision und obwohl es schon Forschung in diesem Bereich gibt, sind wir noch weit davon entfernt eine starke KI entwickeln zu können. Diese Form von KI soll in ihren Eigenschaften der Intelligenz von Menschen entsprechen und darüber hinaus gehen.
Diese beiden Typen von KI unterscheiden sich in vielen Aspekten. Das Forschungsfeld der starken KI ist für unser heutiges Leben mit KI nicht relevant, deshalb werden wir uns im gesamten Kurs nur mit schwacher KI beschäftigen.
Weitere Anwendungen von maschinellem Lernen im Bereich von Gesundheit & Pflege
Das Bewerten von Leberflecken mit KI ist nur eine von vielen Anwendungsmöglichkeiten von KI im Bereich Gesundheit & Pflege. Schauen wir uns jetzt an, welche weiteren Möglichkeiten es gibt.
Auswertung von Bildern und Videos
Maschinelles Lernen findet in vielen Bereichen Anwendung, in denen Bilder oder Videos verarbeitet werden. Diese enthalten oft leichte Variationen, wie zum Beispiel leichte Veränderungen der Lichtverhältnisse oder der Perspektive, die allerdings kein Einfluss auf das Ergebnis haben sollen. Wissensbasierte KI hat es hierbei oft schwer, denn es ist oft nicht leicht, Regeln zu finden, die mit diesen Variationen umgehen können. Hier eignet sich maschinelles Lernen und eine datenbasierte KI oft deutlich besser, denn hier kann die Berechnung deutlich komplexer werden.
Welche Anwendungen fallen dir im Bereich Gesundheit & Pflege ein, bei denen man auch Bild- oder Videomaterial verarbeiten könnte?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
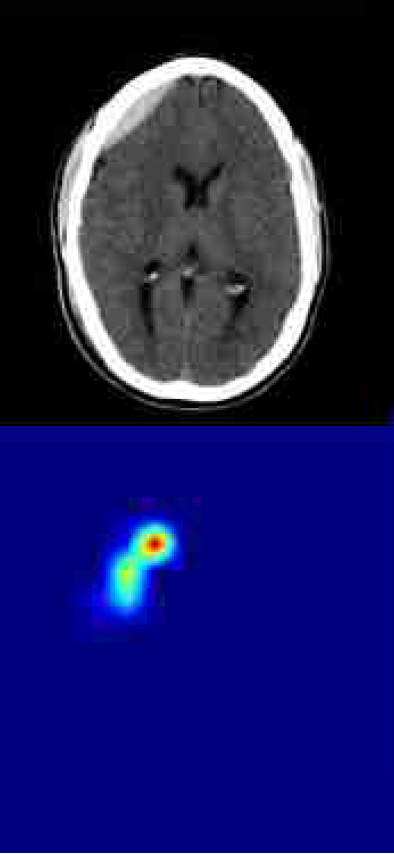
CT Scans beispielsweise sind auch eine Form von Bildern, die mittels KI ausgewertet werden können. Zum Beispiel kann KI dafür genutzt werden, herauszufinden, ob in einem CT-Scan vom Kopf eine Hirnblutung zu sehen ist. Dabei kann die KI nicht nur sagen, ob etwas zu sehen ist, sondern auch den Bereich im CT-Bild markieren.
Bei der Versorgung von pflegebedürftigen Menschen in ihrem eigenen Zuhause können ebenfalls Bild-auswertende KI-System genutzt werden. Beispielsweise kann auf einem Bild erkannt werden, ob ein Mensch gestürzt ist. Dabei erkennt die KI die Körperhaltung des Menschen auf dem Bild und daraus kann man erkennen, ob der Mensch gestürzt ist und nicht mehr von selbst aufstehen kann.

Rückfälle auf die Intensivstation verringern (Unüberwachtes Lernen)
Unüberwachtes Lernen ist eine weitere Gruppe an Verfahren des maschinellen Lernens, neben dem überwachten und verstärkenden Lernen. Unüberwachtes Lernen kann genutzt werden, um Muster bzw. Zusammenhänge in Daten aufzudecken. Im Gegensatz zum überwachten Lernen, welches wir im letzten Kapitel kennengelernt haben, werden beim unüberwachten Lernen keine Trainingsdaten benötigt, die vorgeben, was gelernt werden soll. Stattdessen geben wir dem Algorithmus einen Datensatz und lassen uns von diesem die Frage beantworten: “Welche Muster erkennst du in diesen Daten?” Um zu verstehen, wie das genau funktioniert, schauen wir uns wieder eine konkrete und reale Anwendung an. Hierbei haben wir allerdings einige Vereinfachungen gemacht.
Wenn ein Person auf der Intensivstation im Krankenhaus ist und sich der Gesundheitszustand bessert, stellt sich irgendwann die Frage: Wann hat sich der Gesundheitszustand so weit normalisiert, dass die Person aus der Intensivstation in einen anderen Versorgungsbereich überführt werden kann? Diese Frage ist im manchen Fällen nicht leicht zu beantworten. Laut einer wissenschaftlichen Publikation passiert es in ungefähr 7% der Fällen, dass entlassene PatientInnen innerhalb eines Monats erneut auf die Intensivstation kommen. Das kann darauf hindeuten, dass die kranke Person entweder ursprünglich länger auf der Intensivstation hätte bleiben sollen oder die anschließenden Empfehlungen und Maßnahmen in der Versorgung waren nicht ausreichend.
Auf der Intensivstation werden regelmäßig Gesundheitswerte aufgezeichnet und verschiedene Tests gemacht. Zudem werden allgemeine Informationen über die PatientInnen aufgezeichnet, wie z.B das Alter oder die Dauer des Aufenthalts auf der Intensivstation. Es existieren also eine Vielzahl an Daten über ehemalige PatientInnen bis kurz vor der Entlassung aus der Intensivstation. Zudem ist in diesen Daten auch zu erkennen, ob die Person nach kurzer Zeit erneut auf die Intensivstation kam. Man könnte sich jetzt die Frage stellen:
Gibt es Muster in den Daten ehemaliger PatientInnen und kann man daraus Rückschlüsse ziehen, wie wahrscheinlich eine Person erneut auf die Intensivstation kommt, wenn man sie mit den aktuellen Gesundheitswerten entlassen würde?
Wenn sich hier bisher unbekannte Zusammenhänge finden lassen, wäre es vermutlich möglich, die Rate an Rückfällen weiter zu reduzieren.
Beim unüberwachten Lernen gibt es eine Vielzahl an Verfahren, die man wählen kann. Wir schauen uns hier das Verfahren k-mean clustering an.
Beim k-means clustering versucht der Algorithmus in unserem Beispiel, die PatientInnen in k Gruppen (auch Cluster genannt) aufzuteilen, wobei sich die Daten der Personen innerhalb der Gruppen möglichst ähnlich sein sollen.
Stellen wir uns vor, wir wählen k=3 und erhalten drei Gruppen:



In Gruppe A waren 85% der Personen erneut auf der Intensivstation. In Gruppe B waren 3% der Personen erneut auf der Intensivstation. In Gruppe C waren 70% der Personen erneut auf der Intensivstation.
Werfen wir einen Blick in Gruppe A stellen wir fest, dass hier im Vergleich zu den anderen Gruppen die Dauer des Aufenthalts auf der Intensivstation deutlich höher ist. Das ist noch keine Überraschung, denn es ist anzunehmen, dass eine Person, die lange auf der Intensivstation verbringt, auch anfälliger ist, erneut auf die Intensivstation zu kommen.
In Gruppe C fällt uns allerdings auf, dass bei einem Test im Durchschnitt ein deutlich höherer Wert gemessen wurden als in den anderen Gruppen. Das könnte also ein Indiz sein, um herauszufinden, wie anfällig eine Person ist, erneut auf die Intensivstation zu kommen.
Mit dieser Information könnte man sich jetzt intensiver um diejenigen Personen kümmern, bei denen das Testergebnis hoch war und sie erst dann entlassen, wenn das Testergebnis gesunken ist.
Der k-means Clustering Algorithmus unterteilt die Eingabedaten in Gruppen auf. Dabei gibt es keine Garantie, dass die resultierende Gruppierung uns nachher neue Informationen oder Erkenntnisse liefern.
Wie könnte ein Beispiel aussehen für ein nutzloses Resultat?
Deine Eingaben werden nicht gespeichert und an keinen Server geschickt. Diese Aufgaben sollen dir nur beim Lernen helfen.
Nimm dir ein wenig Zeit für die Aufgabe. Wenn du fertig bist, klicke auf 'Weiter'.
Es könnte zum Beispiel passieren, dass sich nach dem Clustern die meisten Personen in einer Gruppe befinden und die anderen Gruppen fast leer sind. Diese Gruppierung an sich würde uns vermutlich keine neuen Einblicke geben. Allerdings kann ein solches Ergebnis auch nützlich sein, weil wir Sonderfälle (Personen mit ungewöhnlichen Daten) erkennen können und ein erneutes Clustering durchführen können ohne diese Ausreißer in den Daten.
Genauso kann es passieren, dass man aus den Clustern keine neuen Erkenntnisse gewinnen kann. Beispielsweise könnten Patienten nach dem Geschlecht in Gruppen aufgeteilt werden. Hat man dann in allen Gruppen einen ähnlichen Prozentsatz von Patienten, die erneut auf die Intensivstation kommen, hat man keine Information gewonnen. Außer, dass es unterschiedliche Geschlechter unter den Patienten gibt.
Es ist üblich, dass man bei Clustering viel Ausprobieren muss:
- Beim k-mean clustering unterschiedliche Werte für k, also die Anzahl der Cluster, ausprobieren.
- Außreißer in den Daten finden und ausschließen.
- Andere Verfahren, neben dem k-means clustering, ausprobieren.
- Bestimmen, welche Daten und in welcher Form dem Algorithmus gegeben werden.
Zusammenfassend kann man sagen:
Verfahren des unüberwachten Lernens haben das Potenzial neue Muster in Daten aufzudecken, ohne dass man als Mensch ein Ziel vorgeben muss. Dieses fehlende Ziel ist allerdings auch eine Schwäche dieser Verfahren, denn Ergebnisse lassen oft keine neuen Erkenntnisse zu und man muss viel Ausprobieren.
Behandlungsempfehlungen (Verstärkendes Lernen)
Ein weiteres Verfahren beim maschinellen Lernen ist das Verstärkende Lernen.
Verstärkendes Lernen wird genutzt, um Modelle zu trainieren, die über einen Zeitraum hinweg Entscheidungen treffen und damit ein Ziel erreichen wollen.
Bevor wir darauf eingehen, wie das Training bei verstärkendem Lernen funktioniert, schauen wir uns wieder ein konkretes und reales Beispiel für ein KI-System an:
Ein Beispiel aus der Medizin sind KI-gestützte Behandlungsempfehlungen. Hier bekommt die KI die aktuellen Gesundheitswerte der kranken Person und empfiehlt einen nächsten Schritt in der Behandlung. Das könnte zum Beispiel das Verabreichen eines Medikaments oder dessen Dosierung sein. Nach einem bestimmten Zeitraum wird die KI erneut befragt, wieder mit den aktuellen Gesundheitswerten. Darin ist jetzt der Effekt des letzten Behandlungsschritts zu sehen. Haben sich beispielsweise die Gesundheitswerte verschlechtert, empfiehlt die KI vermutlich ein stärkeres Medikament oder eine höhere Dosierung. Die Abfolge aller Behandlungsschritte kann also von Person variieren, je nachdem, wie auf bestimmte Maßnahmen reagiert wird.

Stellen wir uns vor, wir wollen eine KI trainieren, die versucht, zu jedem Zeitpunkt im Krankheitsverlauf eine gute Empfehlung bereitzustellen.
Wenn wir jetzt ein Modell trainieren wollen, stellen wir fest, dass wir nicht wie beim überwachten Lernen eine gewünschte Ausgabe (konkrete Behandlungsempfehlung) vorgeben wollen für eine bestimmte Eingabe (bisherige Gesundheitswerte). Wir wissen ja nicht, welche Behandlungsschritte letztendlich zu einer schnellen Genesung führen werden. Viel wichtiger ist uns dagegen das Ziel, dass die Person nach möglichst wenigen Behandlungsschritten genesen ist.
Für das Training bedeutet das Folgendes: Wir geben kein gewünschtes Verhalten durch Eingabe-Ausgabe-Paare vor. Stattdessen lassen wir das Modell mehrere Schritte einfach machen und ausprobieren, ohne die Modellparameter anzupassen. Sollten wir allerdings auf eine Reihenfolge in den Behandlungsschritten stoßen, die zu einer schnellen Genesung geführt hat, passen wir die Modellparameter an und das Modell wird in Zukunft eher zu ähnlichen Strategien tendieren. Diesen Vorgang nennt man häufig auch Belohnung.
Wichtig bei diesem Verfahren ist, dass das Modell sowohl nach der aktuellen Strategie entscheidet als auch hin und wieder Neues ausprobiert, um auf bessere Strategien zu stoßen.
Verstärkendes Lernen hat viele Parallelen zum Lernprozess von Tieren und Menschen. Wenn wir als Kleinkinder das Laufen lernen, interagieren wir kontinuierlich mit unserer Umgebung. Wir wiederholen, was gut funktioniert hat, probieren aber auch Neues aus, werden manchmal dafür belohnt (wenn wir nicht umgefallen sind) und passen unsere Strategie an. So lernen wir Schritt für Schritt durch die Interaktion mit unserer Umgebung etwas so Kompliziertes zu lernen, wie das Laufen.
Beim Training mit verstärkendem Lernen werden diejenigen Ausgaben “gestärkt”, bei denen man nach einer Anzahl weiterer Schritte eine Belohnung erhalten hat.
Verstärkendes Lernen nutzt in vielen Fällen Simulationen während dem Training. Das heißt, statt mit einem realen System zu interagieren, finden alle Interaktionen in einer Computersimulation statt. In unserem Beispiel würde die Simulation den Krankheitsverlauf der Person simulieren. In der Simulation können dann Behandlungsschritte vorgenommen werden, die einen Einfluss auf die zukünftigen Gesundheitswerte haben. Während dem Training probiert die KI innerhalb der Simulation verschiedene Abfolgen an Behandlungsschritten aus. Um das Ziel einer gesunden Person näher zu kommen, gibt es Belohnungen, wenn ein gesunder Zustand erreicht wird. Bei einer Belohnung wird dann die Abfolge der Behandlungsschritte, die dazu geführt hat, im Modell “verstärkt”. Das heißt, im weiteren Verlauf des Trainings wird es wahrscheinlicher, dass das Modell erneut diese Abfolge ausprobiert. So lernt das Modell kontinuierlich bessere Abfolgen an Behandlungsschritten.
Eine Herausforderung bei verstärkendem Lernen ist das Erstellen der Simulation. Diese sollte so nah wie möglich an der Realität, also an echten Krankheitsverläufen von Menschen, liegen, damit das gelernte Modell auch unter realen Bedingungen gute Empfehlungen gibt. Reale Krankheitsverläufe bzw. wie ein Mensch auf Behandlungsschritte reagiert ist allerdings sehr komplex und hängt von vielen Faktoren ab.
In anderen Anwendungsbereichen kann das Modell auch direkt in der realen Umgebung, also nicht in einer Simulation, trainiert werden. Zum Beispiel, wenn ein Roboterarm einen Gegenstand greifen soll. Beim Ausprobieren während dem Training wird er oft daneben greifen, was aber keine negativen Konsequenzen hat. Bei Behandlungsempfehlungen sollte das Probieren allerdings nicht in an realen Menschen stattfinden.
Um dieses Problem anzugehen, gibt es Ansätze, das Modell mit realen Daten von vergangenen Krankheitsverläufen zu trainieren, bei denen Arztpersonal die Behandlungsschritte gewählt hat. In diesen Daten findet man auch “bessere” und “schlechtere” Behandlungen, mit denen man das Modell trainieren kann. Beim Training kann dann nicht mehr beliebig ausprobiert werden, sondern die Möglichkeiten sind beschränkt auf die Abfolgen in den Daten. Diese Verfahren haben damit den Vorteil, dass sie keine Simulation benötigen und nicht an realen Personen ausprobieren. Allerdings werden beim Training nur diejenigen Abfolgen beachtet, die in den Daten vorkommen, was das Finden komplett neuartiger Abfolgen erschwert.
Verstärkendes Lernen kann gute Strategien nur lernen durch das Ausprobieren. Dieser Prozess ermöglicht es Strategien zu finden, auf die ein Mensch eventuell nicht gekommen wäre. Gleichzeitig bedeutet das aber auch oft, dass die notwendige Trainingsdauer schnell zu groß wird und verstärkendes Lernen unpraktikabel wird. Gibt es zu viele Möglichkeiten und seltene Belohnungen, kann es jahrelanges Training benötigen, bis man zufällig einen Weg zur Belohnung gefunden hat.
Eine Möglichkeit dieses Problem anzugehen ist es, nicht nur für einen gewünschten Endzustand eine Belohnung zu geben, sondern auch für Zwischenzustände, von denen man glaubt, sie führen in die richtige Richtung. Sobald die Belohnung kommt, wird beim verstärkenden Lernen auch häufiger der Weg ausprobiert, der zur Belohnung geführt hat. Leider ist ein gutes Belohnungsschema in der Praxis oft auch keine triviale Aufgabe. Zum einen sind solche Zwischenbelohnungen oft nur eine Annahme, die falsch sein kann. Zum anderen kann das Modell versuchen, nur Wege zu diesen Zwischenbelohnungen zu finden statt zur eigentlichen Belohnung am gewünschten Ziel.
Beim verstärkenden Lernen gibt es eine Vielzahl an Aufgaben, die der Mensch lösen muss. Der Trainingsprozess selbst läuft zwar automatisch ab, allerdings müssen einige wichtige Aufgaben vorher und nachher getan werden, die in vielen Fällen nicht automatisch passieren.
Verstärkendes Lernen hat ein großes Potenzial für den Bereich Gesundheit & Pflege. Allerdings findet man vor allem in diesem Bereich noch viele Grenzen in der Anwendung.
Jetzt haben wir eine Vielzahl an Einsatzmöglichkeiten von KI im Bereich Gesundheit & Pflege kennengelernt. Außerdem haben wir einige Möglichkeiten & Grenzen von maschinellem Lernen im Allgemeinen verstanden. Das gibt uns eine Vorstellung davon, was mit KI möglich ist und auch worauf man beim Einsatz von KI achten sollte. Speziell bei datenbasierter KI gibt es zwei weitere Herausforderungen, die man berücksichtigen sollte, welche wir im nächsten Kapitel kennenlernen werden.